AI: from deep learning to in-memory computing
AI: from deep learning to in-memory computing
Includes PDF, HTML & Video, when available Members: $17.00 Non-members: $21.00 ADD TO CART
www.spiedigitallibrary.org
2019년 3월 26일AI : 깊은 학습에서에 인 메모리 컴퓨팅
절차 볼륨 10959, 마이크로 리소그래피 XXXIII에 대한 계측, 검사, 및 공정 제어; 109591J (2019) https://doi.org/10.1117/12.2517237
이벤트 : SPIE 고급 리소그래피 , 2019, 산호세, 캘리포니아, 미국
요약
지난 몇 년 동안, 인공 지능 (AI)는 강렬한 미디어 과대 광고의 대상이되어왔다. 기계 학습, 깊은 학습 (DL), 및 AI 기술 마음 간행물 종종 외부의 수많은 기사에서 온다. 인공 지능 과대 광고가 계속 성장, 소음에 신호를 인식 할 수 있도록 무엇을 단순히 과대 보도 자료에서 세계 변화 발전을 따로 이야기하는 것이 중요하다. 이 논문은 작업 방법과 GPU (그래픽 처리 단결이) 그것을 현실로 만들 수있는 방법을 깊이 학습을 설명하려고합니다. 마지막으로, 메모리 DL에 대해 (IMC)를 계산 미래의 높은 성능과 낮은 전력 DL 하드웨어 개발 방향을 가리 키도록 도입된다.
회의 발표
동영상 재생
쇼 성적 증명서
1.
소개
최근 몇 년 동안, DL [ 1] 점점 이미지를 분류 연설을 이해, 비디오 게임과 거의 인간의 기술 수준으로 언어를 번역하는 등의 작업에 향상되었습니다. 더 중요한 것은, 이러한 발전은 소셜 미디어 사이트에 영향을 미치는 쇼핑과 추천인 시스템, 은행 및 금융, 다수의 클라우드 기반 컴퓨팅 애플리케이션, 심지어 휴대 전화와 실 생활에서 상업적으로 널리되기 위해 DL 시스템을 사용할 수있다. 하향 링크 모델은 조정 가능한 매개 변수의 수백만 거대한 자기 조직화 시행 착오 기계 같다. 빅 데이터와 기계를 공급하고 수십 훈련 사이클의 수백만의 수백 반복 진행 한 후, 기계는 DL 모델에 관한 최선의 매개 변수 및 가중치를 찾을 수 있습니다. 현재 GPU 카드는 DL에 가장 적합한 하드웨어 솔루션입니다 인해에 병렬 행렬 곱셈 기능 및 지원 소프트웨어의 우수한. 그러나, 유연성 (게임 지원) DL하기에 덜 효율적 및 기타 DL은 ASIC (주문형 반도체)를 가속기 더 나은 효율과 성능을 제공하기 위해 올 곳이다. 그러나 GPU와 ASIC 모두 기존의 폰 - 노이만 아키텍처를 기반으로한다. 메모리 및 프로세서 (소위 "폰 - 노이만 병목") 사이의 시간과 에너지 소비 반송 데이터는 특히 실시간 화상 인식하고, 자연 언어 처리 등의 데이터 중심 애플리케이션에 대해, 문제가되고있다. 더 큰 가속 인자를 달성하고 - 폰 노이만 아키텍처 이상의 전력을 낮추기 위해, IMC 비 휘발성 메모리 (NVM) 배열에 기초하여, 상 변화 메모리 (PCM)와 저항 랜덤 액세스 메모리 (RRAM) 등이 모색되고있다. IMC를의 벡터 행렬 곱셈은 CPU / GPU (디지털 회로) 및 /에서 메모리로 무게 이동을 피에 비싼 높은 전력 소비 행렬 곱셈 연산을 대체합니다. 그 결과, DL의 성능과 전력 소비에 큰 영향을 미칠 수있는 큰 잠재력을 가지고있다.
2.
AI의 간략한 역사
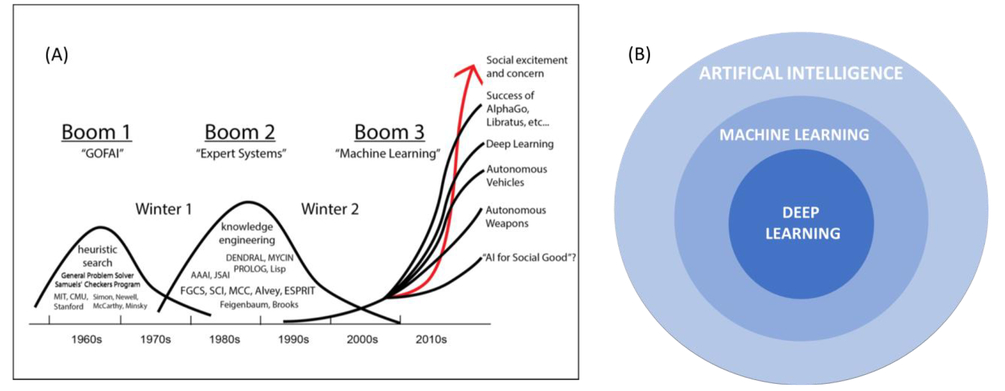
AI는 1950 년대 [에서 태어난 이 컴퓨터 과학의 시작에 불과 필드는 컴퓨터가 만들어 질 수 있다면 그 결과 우리는 오늘날에도 여전히 모색하고 있습니다 -a 질문에 "생각"묻기 시작에서 개척자의 소수로,]. 필드 간결한 정의는 일반적으로 인간에 의해 수행 지적 작업을 자동화하기위한 노력 일 것이다. 상당히 오랜 시간 동안 많은 전문가들은 인간 수준의 인공 지능 프로그래머가 지식을 조작하기위한 명확한 규칙의 충분히 큰 세트를 공예함으로써 간단하게 달성 할 수있다 믿었다. 도 1 도시의 AI 세 붐. 첫 번째 붐은 GOFAI입니다. 존 하 우즈 랜드는 이름 GOFAI ( "좋은 오래 된 구식 인공 지능") 준 (3)]. 그것은 문제, 논리와 검색의 높은 수준 "상징적"(사람이 읽을 수있는) 표현을 기반으로 인공 지능 연구의 모든 방법의 수집에 대한 용어입니다. GOFAI의 주요 부분은 휴리스틱 검색, 따라 분기를 결정하기 위해 이용 가능한 정보를 기반으로 각 분기 단계에서의 검색 알고리즘의 대안을 위 기능입니다. 두 번째 붐은 인간 전문가의 의사 결정 능력을 모방하는 현실 세계의 문제에 대한 해결책을 제공하기 위해 지식, 규칙 및 추론 메커니즘의 많은 양을 포함하는 컴퓨터 시스템 전문가 시스템입니다. 다음의 경우-오히려 기존의 절차 적 코드를 통해보다 규칙으로 전문가 시스템은 지식의 몸을 통해 추론하여 복잡한 문제를 해결하기 위해 설계, 주로 표현.4 ]. 휴리스틱 검색 및 전문가 시스템은 체스뿐만 아니라 정의, 논리적 인 문제를 해결하기에 적합 증명하지만, 이러한 영상 분류, 음성 인식, 또는 더 복잡한, 퍼지 문제를 해결하기 위해 명시 적 규칙을 파악하기 어려운 것으로 밝혀졌다 언어 번역. AI의 세 번째 붐은 자신의 자리를 차지할 발생 : 기계 학습 (ML).
그림 1. 다운로드
(A) AI의 세 가지 붐 : GOFAI ( "좋은 구식 인공 지능") 상징적 인 AI, 전문가 시스템 및 기계 학습 [ 3 ]. (B) 인공 지능, 기계 학습과 깊은 학습의 관계.

ML은 새로운 개념이 아니다. 1959 년 아서 사무엘, ML의 개척자 중 하나는 "컴퓨터를 명시 적으로 프로그램을받지 않고 학습 할 수있는 기능을 제공합니다 연구 분야"[로 기계 학습을 정의 5 ]. 즉, ML 프로그램은 위의 경우 - 다음 문장처럼 컴퓨터에 명확 입력되지 않았습니다. ML 프로그램은 어떤 의미에서, 그들은에 노출하고있는 데이터에 대한 응답으로 자신을 조정합니다. ML은 얼마나 필요없이 배울 수있는 컴퓨터 교육에 초점을 맞추고은 [특정 작업에 프로그래밍 할 것을 AI의 하위 지점이다 (6)]. 사실, ML 뒤에 핵심 아이디어는 배우와 데이터에 대한 예측을 알고리즘을 만들 수 있다는 것입니다. 그것은 더 많은 데이터에 노출되면 자체를 수정할 수있는 기능이있다; 즉, 기계 학습은 동적이며 없습니다 특정 변경을 인간의 개입을 필요로한다. 즉, 덜 취성, 인간 전문가에 덜 의존한다. ML 깊은 학습 알고리즘의 개발을위한 50 년 동안 기다렸다. 깊은 학습은 ML 붐은 컴퓨터 기술 (GPU), 현대 기계 학습 알고리즘 (DNN)와 빅 데이터의 가용성의 교차점과 함께 현실이 될 수있다. 딥 러닝 머신 학습의 서브 세트이며, 도시 된 바와 같이 전류는 기계 학습의 핵심 인 도 1 (B).
삼.
인공 신경망
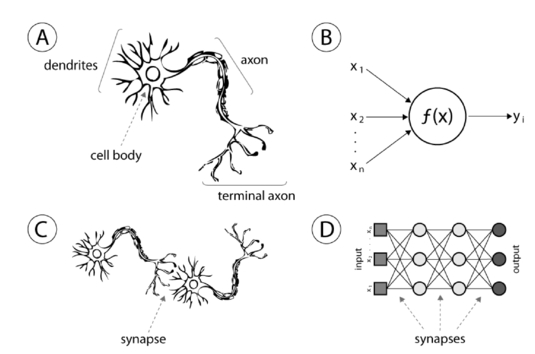
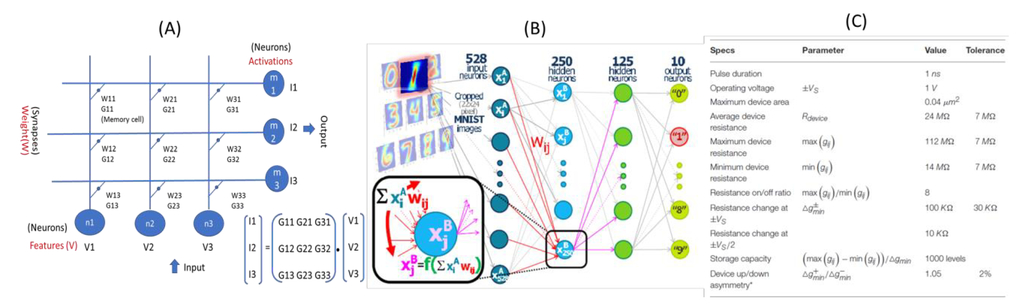
인공 신경망 (ANN)는 DL의 기본 프레임 워크로, 인공 뉴런의 조합입니다. 도 2 도시의 예 인간 인공 신경 뉴런 (AN). 인간 신경 유사하게는 ( 도. 2 B)은 덴 드라이트의 입력 정보 (XI)를 획득하고, 축색 돌기 (일)를 통해서 출력 정보를 제공한다. 의 화살표 도. 2 B는 특정 입력 또는 뉴런의 시냅스 유사한 출력 가중치를 나타낸다. 시냅스 신경 네트워크를 형성하기 위해 각각의 뉴런을 연결 가중치에서 본 바와 같이 ANN을 형성하기 위해 각 노드의 연결 도. 2 C, 2 D. 도 3ANN이 집의 값을 예측하는 훈련 방법을 설명합니다. 예측 같이 집 값이, 집의 기능 및 최적화 된 가중 인자의 모든 제품을 추가하는 것입니다 (추론) 그림 3(A), 가중치] 및 [특징]의 행렬 (벡터) 간 제품 등. 교육의 경우, 집의 특징 데이터 이전 훈련 된 가중치 조합으로 예측 집 값을 얻기 위해 ANN에 공급된다. 예측 된 값과 실제 값 사이의 차이는 손실 (에러)이다. 교육의 목적은 손실을 최소화하기 위해 무게 조합을 수정하는 것입니다. 어떻게 손실을 최소화 하는가? 한 가지 방법은 순서 곱 입력은 입력 자연 추측을 할 수있는 프레임 워크를 구축하는 것입니다. 다른 출력 / 추측은 입력 및 알고리즘의 산물이다. 일반적으로, 초기 추측은 아주 잘못, 하나의 입력에 관한 지상 진실 라벨을 가지고 운이 충분한 경우, 하나는 진실을 대조하여 추측이 얼마나 잘못 측정 한 다음 알고리즘을 수정하는 그 오류를 사용할 수 있습니다 . 즉 신경 네트워크가하는 일입니다. 그들은 손실 (오류)를 측정하고이 덜 오류를 달성 할 수있을 때까지 자신의 매개 변수를 수정 계속. 그들은 짧은, 최적화 알고리즘이다. 잘 조정 된 경우, 추측과 추측하고 다시 추측에 의해 자신의 오류를 최소화 할 수 있습니다.
그림 2. 다운로드
(A) 인간 뉴런 (B), 인공 신경 또는 숨겨진 화합 (C) 생물학적 시냅스 (D) ANN 시냅스 [ 7 ].

그림 3. 다운로드
(A) 사용은 ANN (2 층, 5 개 뉴런) 집의 값을 예측합니다. 범죄 비율, 세금, 방 번호 및 학군 집의 기능 (입력 X)입니다. 값 (출력 Y)는 각 기능의 가중치 (w) 공정에 의해 결정된다. 집 값을 예측하기 ANN (무게) 교육 (B)는 다음과 같은 작업의 반복이다 : 1. 훈련 데이터 (다른 기능을 가진 진짜 집 베일 데이터의 수천) 예상 손실을 계산하는 데 사용됩니다. 2. 무게는 손실을 줄이기 위해 업데이트됩니다. 가장 정확한 ANN을 달성하기 위해 (C)는 가중치의 조합을 최적화함으로써, 예측 손실을 최소화하는 것이다.

4.
DEEP 학습
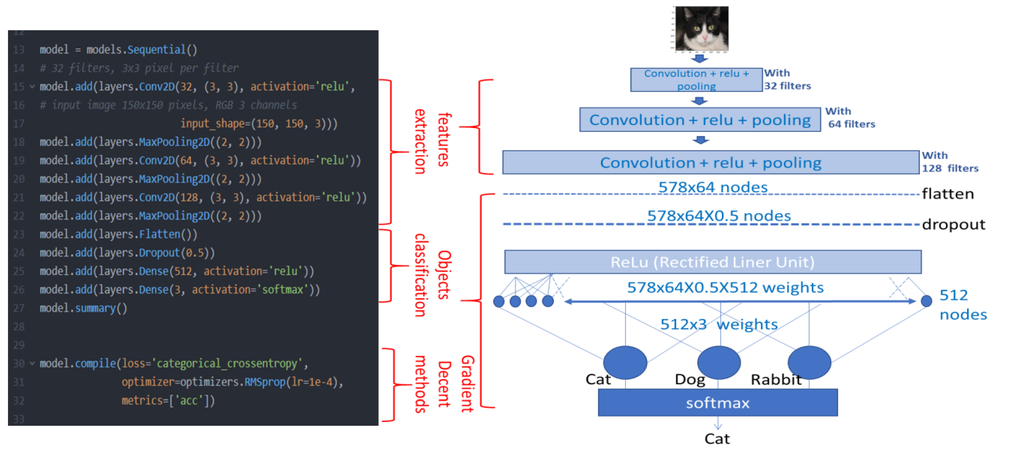
사람들이 용어 DL을 사용할 때 일반적으로, 그들은 깊은 인공 신경망 (DANN 또는 DNN)를 참조한다. 도시 된 바와 같이, AN에 깊은 수단 이상의 층이며, ANN에 첨가되어 ,도 2 (D). 현재의 추세에서, 더 깊은 DNN 더 preformation있다. 그것은 예를 들어 등 이미지 인식, 음성 인식, 추천인 시스템과 같은 많은 중요한 문제에 대한 정확성에 새로운 기록을 설정하고, 깊은 학습은 이동에서 전 세계 챔피언 이세돌을 이길 DeepMind의 잘 알려진 AlphaGo 알고리즘의 일부입니다 초기 2016 년에하지만 더 레이어를 추가하는 비용은 인해 더 많은 기능과 최적화 할 필요가 무게에 기차에 DNN을 더 어렵게 만드는 것입니다. 활성화 및 드롭 아웃 [같은 -이 문제 여러 기능 (층)을 해결하기 위해 8- 상기 DNN 첨가된다. 활성화 함수는 DNN에 비선형 특성을 도입하기 위해 사용하고, 대중 하나 하나 ReLU (정류 라이너 단위)이다 9 부극 번호 OUT] 화면. 드롭 아웃은 무작위로 DNN에서 신경 세포 (노드)의 일정 비율을 제거하는 것입니다. 콘볼 루션 신경망 (CNN) [ 10 ] 분류 또는 컴퓨터 비전에 객체를 검출하는데 사용되는 가장 중요한 앤스 중 하나이다. 그림 4왼쪽 쇼에서 CNN의 오른쪽에 파이썬 언어 코드는 고양이, 개, 토끼 3 종류의 영상 분류를 만들기 위해 자사의 모델입니다. 본질적으로 CNN은 두 부분으로 구성됩니다. 하나는 특징 추출 컨벌루션 층이고, 다른 하나는 물체의 분류에 대한 완전히 연결 층이다. 컨벌루션 층 단순히 작은 가중치 행렬 (제 1 층 (32 개)은 3 × 3 필터를 가짐) 인 필터 (커널)로 시작한다. 그것의 현재의 입력 부분과 함께 elementwise 곱셈을 수행하고 하나의 출력 픽셀에 대한 결과를 합산 입력 데이터에 대한이 필터 "슬라이드"(픽셀 / 숫자로 표시되는 화상). 화상 전체를 통해 편 후, 각 필터는 ReLU 동작의 입력으로 필터링 된 이미지를 생성한다. 풀링 필터링 된 이미지를 압축하는 처리이다. 이는 압축 된 필터링 된 이미지를 생성하는 새로운 화소를 생성하는 이웃 픽셀 수집. MaxPooling2D ((2,2))에 인접하는 4 개 화소 중 단지 최대 화소 (수)가 사용되는 방법. CNN의 컨볼 루션과 풀링 층을 직접 시각 신경의 단순 셀 고전 개념 복잡한 세포에서 영감 [11 ]. 세 컨벌루션 연산 후에 될 복잡한 이미지가 완전히 연결 층에 연결하는 화소 (기능 / 뉴런)의 1 차원 벡터로 2 차원 배열에서 "평탄화". 분류, 동작은 유사하다 도 3 하지만 DNN 3 층이된다. 마지막 숨겨진 레이어의 512 개 노드 (뉴런) 512x3 = 1536 무게 (시냅스)과 다음 층의 3 개 노드에 연결되어 있습니다. 3 개 출력 노드의 벡터 값은 ((512)의 기능) -matrix (3 × 512 중량) 승산함으로써 계산된다. 출력 노드에서의 최대 값은 소정의 객체 (CAT)의 최대 수를 나타낸다. 배치 구배 하강 알고리듬은 [ 12 ] RMSprop 최적화이 모델 [훈련하기 위해 사용된다 (13)]. 그라데이션 하강과 종류는 DNN 훈련을위한 유일한 알고리즘, 그리고 그 다른 최적화는 훈련 속도를 개선하는 데 사용됩니다. 교육 과정은 계층에서 네트워크 계층의 가중치를 조정하는 것입니다. (w, 각 중량의 갱신 지은 )이다 : W- 지 승 ← 지 + η • δ J • X I 여기서 η 인 학습율 및 δ j는 다시 다음의 인접 층의 노드 J로부터 전파 손실 (에러)이고 . X 나 노드 I의 입력된다.
그림 4. 다운로드
객체의 CNN (왼쪽)와 (오른쪽)의 모드의 파이썬 코드 (고양이, 개, 토끼) 분류.

5.
HARDWARES 깊은 학습
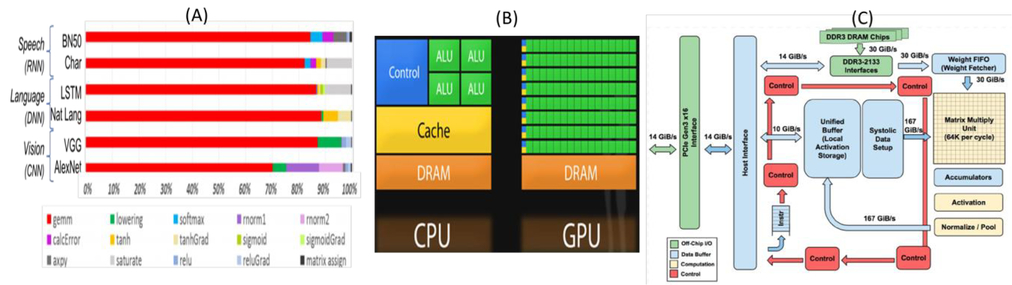
도 5 (A)은 [ 14 ]에 나타낸다 DL 알고리즘은 동작의 스펙트럼으로 구성된다. 행렬 곱셈 (GEMM)가 지배적이지만, 성능, 효율을 최적화하는 것은 정확도를 유지하는 것이 효율적 보조 기능 모두를 지원하는 코어 아키텍처를 필요로있다. 그림 5(B)는 CPU와 GPU의 비교를 나타낸다. 중앙 처리 장치 (CPU)는 예컨대 타임 슬라이싱 같은 복잡한 작업을 처리 할 수 있도록 설계되어 있으며, 복잡한 제어 흐름과 반대로 등 분지, 보안, 그래픽 처리 단결 (GPU는) 단 한 가지 잘. 그들은 같은 행렬 곱셈 등의 반복 낮은 수준의 작업 수십억을 처리합니다. GPU는 산술 논리 단위의 수천 (ALU가) 일반적으로 단지 4 또는 8을 가지고 있지만, GPU가 다른 응용 프로그램과 소프트웨어의 수백만을 지원하는 범용 프로세서는 여전히 기존 CPU에 비해. 개의 ALU의 수천 매 계산를 들어, GPU는 중간 계산 결과를 읽고 저장하는 액세스 레지스터 나 공유 메모리를 필요로한다. , GPU가 수행의 ALU는 수천 이상의 병렬 계산을하기 때문에 또한 비례 적으로 더 많은 에너지 액세스 메모리를 소비하고 복잡한 배선 GPU의 풋 프린트를 증가시킨다. 이러한 문제를 해결하기 위해 [DL위한 ASIC이 필요하고, TPU (텐서 처리 장치)도 15는 상기 실시 예의 하나이다. 그림 5(c)는 TPU 칩의 블록도이다. 그것은 훨씬 적은 전력과 작은 물리적 공간의 내부를 소모하면서 엄청나게 빠른 속도로, 신경 네트워크의 대규모 곱셈 및 추가 처리 할 수있는 신경망 워크로드에 대한 전문 매트릭스 프로세서입니다. 그 핵심 요소는 폰 노이만 병목 (메모리에서 데이터를 이동)의 주요 감소이다. DNN 그것을 승수와 가산기의 TPU 장소 수천, 후에 가서 그 운영의 큰 물리적 매트릭스를 형성하기 위해 서로 직접 연결할 있는지 알면. 승산기 및 가산기의 행렬로 메모리로부터 제, TPU 부하 무게의 동작 내용. 그런 다음, 메모리에서 TPU 데이터를로드 (기능). 각각의 승산이 실행되는 동시에 가산하면서, 그 결과는 다음 승산기로 전달된다. 따라서, 출력 데이터 및 파라미터 간의 모든 승산 결과의 합이 될 것이다. 대규모 계산 및 데이터 전달의 전 과정 동안 어떤 메모리 액세스는 전혀 필요하지 않다. TPU의 단점은 유연성을 잃고있다; 그것은 단지 몇 가지 특정의 신경 네트워크를 지원합니다.
그림 5. 다운로드
깊은 학습 알고리즘의 (A) 작업 스펙트럼. CPU와 GPU의 (B)와 비교. (C)는 TPU의 블록도.

6.
깊은 학습을위한 IN-메모리 컴퓨팅
DNN의 추론 및 훈련 알고리즘은 주로 전후 방향으로 벡터 행렬 곱셈 연산을 포함한다. 그것이 50 년 이상 [전 제안 된대로이 작업은 2 차원 크로스바 메모리 어레이에 IMC에 의해 수행 될 수있다 (16) ]. 도시 된 바와 같이 ,도 6(A) 상기 DNN의 무게 (G)가 1T (트랜지스터) -1R (저항) 또는 1T 셀이 될 수있는 메모리 셀에 저장된다. 동시에 행에서 입력 전압 V를인가함으로써 I는 열의 아날로그 가중 (G)의 합이 전류 키르히 호프 법칙 및 옴의 법칙을 통해 이루어진다 전류 출력을 읽었다. I는 전류 I. IMC를 입력 전압 V, 컨덕턴스 G로 행렬 및 출력에 매핑 입력 벡터에 의해 수행되는 V G. 벡터 행렬 곱셈 = 이상적인 크로스바 메모리 어레이에 입력 - 출력 관계는 다음과 같이 표현 될 수있다 벡터 행렬 곱셈은 고가의 전력 소비 행렬 곱셈 GPU / TPU의 동작 (디지털 회로) 및 메모리로부터 가중치 이동을 피를 대체하고, 그 결과, 크게 DNN의 비록 성능 및 전력 소비를 개선한다.17 2,140 × [을] 18 ] 전력과 면적에서 상당한 감소. 도 6 DNN 시연 한 시냅스 (중량) 및 각 층의 뉴런으로 PCM 장치를 이용하여 추론 (B)에 도시 한 가중치 종째 통해 다음 층 및 비선형 F ()를 구동한다. 입력 뉴런 연속 MNIST 이미지의 픽셀에 의해 구동된다; 10 개 출력 뉴런 제시 한 자릿수 식별 [ 19]. IMC DNN 가속도의 한계는 상기 메모리 장치의 결함이다. 소자 특성은 일반적 DNN 훈련의 가속도가 제한되고있다 같은 비 온 / 오프 높은 디지털 비트 단위 저장 또는 비대칭 리 세트 동작 등에 무관 특성 같은 메모리 애플리케이션에 유익한 것으로 간주된다. IMC DNN위한 완전한 메모리 셀에서와 같이 ,도 6 완전한 저항성 장치에 대한 특정 요건을 강요하며하는 30000X 가속 인자가 달성 될 수있다 (c) 플러스 시스템 및 CMOS 회로의 설계 [ 20]. DNN의 IMC는 여전히 아직 시장에 제품이없는 큰 장점이 있습니다. 일어나지 않도록 과제 포함 : 메모리 셀 (1)의 결함 (사이클 내구성, 작은 동적 범위, 저항 편차, 비대칭 프로그램). 층 (AD, DA 변환, 디지털 기능 연결) 사이의 2 데이터 전송. 3. 유연한 소프트웨어 프레임 워크 지원 (IMC DNN 재구성 소프트웨어).
그림 6. 다운로드
깊은 학습 알고리즘의 (A) 작업 스펙트럼. CPU와 GPU의 (B)와 비교. (C)는 TPU의 블록도.

7.
결론
고급 알고리즘의 도움과 컴퓨팅 하드웨어 (GPU)와 함께 깊은 학습은 다음 단계로 AI를 푸시합니다. 에서 병렬 처리의 ALU 메이크 GPU는 강력한 기계 수천 DNN 동작 행렬 곱셈을 수행한다. 유연성을 희생하여, ASIC 등의 TPUs는 DNN 가속 칩은 더 높은 성능과 낮은 전력을 달성 할 수있는 구성. 그러나 행렬 곱셈을 수행하는 디지털 회로를 사용하여 자신의 한계가있다. 더 높은 가속 인자와 낮은 전력을 달성하기 위해, 메모리 내 DNN 벡터 행렬 곱셈 연산이 제안되었다. IMC는 DNN에 대한 큰 혜택을 생성하지만, 많은 도전이 여전히 존재한다. 예를 들어 메모리 셀 결함, 레이어 및 지원되는 소프트웨어 및 프레임 워크 사이의 데이터 전송은 IMC DNN이 현실이되기 전에 극복해야합니다.
참조
[1]
얀 레컨, 요 수아 벤 지오 & 제프리 힌튼, "깊은 학습", 자연, 권. 512, 436-444 (2015). https://doi.org/10.1038/nature14539 Google 학술 검색
[2]
S. 러셀 & P. 노르 빅, "인공 지능 : 현대적인 접근", 프렌 티스 홀 (2003). Google 학술 검색
[삼]
콜린 가비는, "약속 및 빈 위협 브로큰 : 다음은 미국, 1956-1996에서 AI의 진화"기술의 역사 3 월 12 일, 2018, 사회 http://www.technologystories.org/ai-evolution/을 (12 2019년 1월). Google 학술 검색
[4]
존 하 우즈 랜드, "인공 지능 : 바로 그 아이디어", 케임브리지, 매사추세츠 : MIT 보도 (1985). Google 학술 검색
[5]
아서 사무엘, "체커의 게임을 사용하여 기계 학습의 일부 연구", 연구 개발 IBM 저널. 권. 3, 3 번. 7 월 535-554 (1959). https://doi.org/10.1147/rd.33.0210 Google 학술 검색
[6]
CM 주교, "패턴 인식 및 기계 학습", 스프링, (2006). Google 학술 검색
[7]
비니 Maltarollo 등, 인공 신경망-아키텍처 및 응용 프로그램, ED "화학 문제에 인공 신경 회로망의 응용 프로그램". K. 스즈키, 인텍, 203-223 (2013) Google 학술 검색
[8]
알렉스 Krizhevsky, 일리아 Sutskever & 제프리 힌튼, "깊은 길쌈 신경망과 ImageNet 분류", PROC. 신경 정보 처리 시스템의 발전 (25) 1090-1098 (2012). Google 학술 검색
[9]
자이 Glorot 앙투안 Bordes 및 요 수아 벤 지오는 PROC "깊은 정류기 신경망 성긴". 인공 지능 및 통계 315-323 (2011)에 14 번째 국제 회의. Google 학술 검색
[10]
얀 레컨, 등., "백 전파 네트워크와 필기 숫자 인식", PROC. 신경 정보 처리 시스템 396-404 (1990)의 발전. Google 학술 검색
[11]
DH HUBEL 및 TN 위젤, "받아들이는 필드, 양안의 상호 작용, 그리고 고양이의 시각 피질의 기능적 아키텍처", J. Physiol. 160, 106-154 (1962). https://doi.org/10.1113/jphysiol.1962.sp006837 Google 학술 검색
[12]
데이터 과학자 9 월 (17), 2017 향해 Aerin 김 "일괄 그라데이션 하강 및 확률 그라데이션 하강의 차이", https://towardsdatascience.com/a-look-at-gradient-descent-and-rmsprop-optimizers-f77d483ef08b , ( 2019년 1월 18일). Google 학술 검색
[13]
데이터 과학자 이세 (19), 2018 향해 Rohith 간디 "그라데이션 하강과 RMSprop 최적화에서 봐", https://towardsdatascience.com/a-look-at-gradient-descent-and-rmsprop-optimizers-f77d483ef08b (18 2019년 1월). Google 학술 검색
[14]
B. 플라이셔 등., "AI 교육 및 추론을위한 확장 가능한 멀티 테라 OPS 깊은 학습 프로세서 코어", 심포지엄 VLSI에 회로, C4-2, (2018). Google 학술 검색
[15]
노먼 P. Jouppi 등. "텐서 처리 장치의 인 - 데이터 센터 성능 분석", PROC. 44 컴퓨터 구조에 대한 연례 국제 심포지엄, 1-12 (2017). Google 학술 검색
[16]
Kybernetik Steinbuch, "Dielernmatrix"Kybernetik (1), 36-45 (1961). https://doi.org/10.1007/BF00293853 Google 학술 검색
[17]
. GWBurr 등, "시냅스 중량 소자와 같은 비 휘발성 메모리로 구현 대규모 신경망 : 비교 성능 분석 (정확도, 속도, 전력)"PROC. IEDM 15, 76-79 (2015). Google 학술 검색
[18]
J. 서는 외., 나노 (TNANO), 집에 IEEE 트랜잭션 "온 - 칩 CMOS 학습 및 저항 시냅스 장치 가속 성긴". 14, 6 호, 969-979 (2015). https://doi.org/10.1109/TNANO.2015.2478861 Google 학술 검색
[19]
GWBurr 외., PROC "시냅스 중량 소자로서 상 변화 메모리를 사용하여 실험적 증명하고 대규모 신경망 (165,000 시냅스)의 공차". IEDM 14, 697-700 (2014). Google 학술 검색
[20]
타이푼 Gokmen 및 Yurii 블라 소프, "저항 크로스 포인트 장치와 깊은 신경 네트워크 교육의 가속"앞입니다. Neurosci, 있습니다 volum (10), 기사 (333), (2016). https://doi.org/10.3389/fnins.2016.00333 Google 학술 검색
© (2019) 사진 광학 계측 엔지니어의 저작권 협회 (SPIE). 추상의 다운로드는 개인 사용 만 허용됩니다.
'인공지능' 카테고리의 다른 글
| 초당 40조 번 연산하는 'AI 반도체' 국내 기술로 개발 (0) | 2020.04.17 |
|---|---|
| 인텔, 첫 AI 전용 ASIC '너바나 NNP' 공개 (0) | 2019.11.15 |
| 삼성전자, 5G 모바일 프로세서 ‘엑시노스 980’ 공개 (0) | 2019.11.15 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}